 100% sicuro | Senza pubblicità |
100% sicuro | Senza pubblicità |
La tecnologia PDF ha notevolmente migliorato il regno della digitalizzazione degli archivi negli ultimi decenni. Quello che una volta era un compito impegnativo per la conservazione dei dati e la capacità di archiviare i documenti per un facile recupero è ora diventato un luogo comune. Uno dei fattori chiave che ha guidato questo cambiamento è l'OCR o il riconoscimento ottico dei caratteri. Vediamo perché L'OCR svolge un ruolo così importante nella digitalizzazione degli archivi, come viene applicato come processo e come l'accuratezza dell'OCR può essere migliorata attraverso vari metodi.


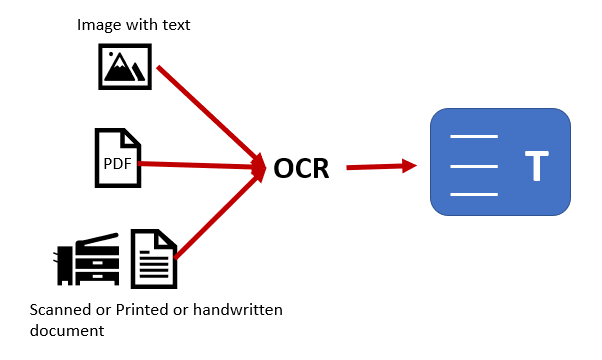
Parte 1. Applicazione dell'OCR nella digitalizzazione degli archivi
OCR è essenzialmente il processo di riconoscere, estrarre e incorporare il contenuto del testo da un documento digitale o fisico basato su immagini nello strato dell'immagine esistente. Questa tecnologia a doppio strato è supportata da PDF, rendendolo un mezzo ideale per la digitalizzazione degli archivi. Ci sono diverse altre considerazioni che rendono il PDF il veicolo perfetto per digitalizzare gli archivi di documenti.
1. Innovare le metodologie tradizionali di catalogazione e indicizzazione
Catalogazione e indicizzazione vanno spesso di pari passo, ma sono due processi completamente diversi. Mentre la catalogazione è l'organizzazione delle risorse o dei contenuti, l'indicizzazione è legata al recupero delle informazioni. Entrambi sono necessari quando si archiviano documenti, media audiovisivi, giornali, riviste, riviste accademiche e altri tipi di contenuto. La catalogazione ti dice cosa è disponibile, mentre l'indicizzazione offre un modo per trovare l'informazione corretta che stai cercando.
Convertire documenti fisici o file scansionati in PDF permette di catalogare e indicizzare allo stesso tempo utilizzando la tecnologia OCR. Il contenuto digitalizzato può essere reso modificabile o ricercabile, permettendo una facile catalogazione e indicizzazione dell'archivio. Pertanto, l'OCR è in realtà un nuovo modo di catalogare e indicizzare gli archivi di documenti, rendendo il processo accessibile attraverso i computer.
2. Realizzare il vero Full-Text Retrieval
L'indicizzazione manuale è tipicamente incline all'errore umano, che può variare dal 3% al 30% a seconda del compito da svolgere. Questo significa che i documenti basati sul testo potrebbero non essere indicizzati correttamente se il processo è condotto manualmente. Lo stesso vale anche per la catalogazione, ma in misura minore. Tuttavia, con l'aiuto dell'OCR, la conversione è possibile fino a un tasso di precisione del 98% - 99%. A sua volta, questo permette la ricerca e il recupero del testo completo. Quando questa capacità è presa in tandem con i metadati e gli elementi di indicizzazione, dà luogo a un sistema di catalogazione e indicizzazione migliorato.
3. Tecnologia PDF a doppio strato
Anche se la comprensione generale è che l'OCR incorpora uno strato di testo sull'immagine esistente, in realtà, è reso come testo invisibile all'interno del PDF. Tuttavia, questo testo può essere selezionato ed è quindi ricercabile. Nel processo di digitalizzazione dell'archivio, l'archivista verificherà prima se lo strato di testo digitalizzato è coerente con il testo nell'immagine originale. Questo passo di garanzia della qualità è fondamentale per l'accuratezza del testo renderizzato. Tali modifiche saranno poi memorizzate nella copia OCR del file, rendendo più facile la ricerca con parole chiave. Qualsiasi errore di battitura che viene tralasciato durante questo controllo di qualità renderà il documento non ricercabile per quella particolare parola chiave. È qui che entra in gioco la stratificazione. Permette all'archivista di controllare visivamente se i caratteri riconosciuti dal motore OCR sono coerenti con quelli del file originale basato sull'immagine.
4. Espandere l'uso dei file archiviati
Eseguire l'OCR su un documento PDF rende un livello ricercabile, ma può anche rendere il testo modificabile. Tuttavia, ai fini dell'archiviazione e del recupero, un documento ricercabile è preferito perché le informazioni di indicizzazione possono aiutare a restituire risultati di ricerca full-text. Per esempio, è molto più facile correggere un pezzo di testo in un file basato sull'immagine usando l'OCR che correggere lo stesso testo in uno strumento di editing dell'immagine. OCR opens up a range of such use case possibilities that traditional archiving techniques cannot match.
Parte 2. Come migliorare il tasso di riconoscimento OCR
L'accuratezza di un'esecuzione OCR dipende da varie considerazioni sia basate sul software che manuali, e queste sono elencate di seguito. Ognuno di questi parametri permette all'OCR di essere più accurato, e possono essere controllati sia nella fase pre-OCR che in quella post-OCR, durante il controllo di qualità.
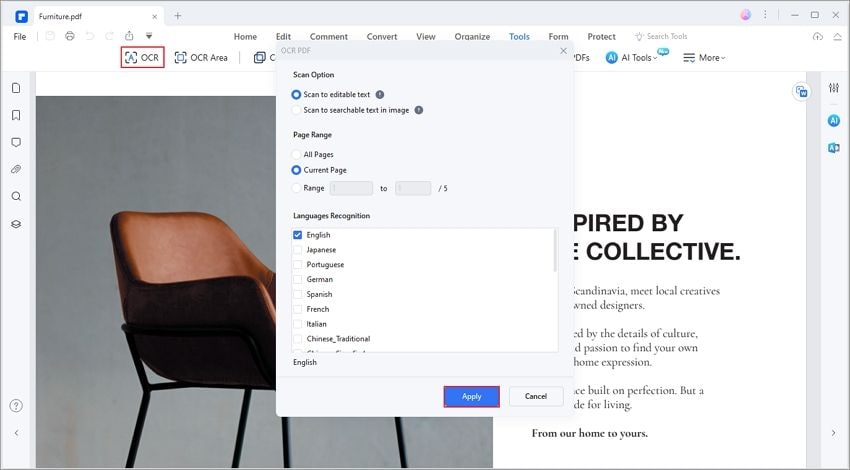
1. Usare il software giusto - PDFelement
Il plugin OCR in PDFelement è altamente accurato e lavora con più lingue, anche contemporaneamente. Inoltre, PDFelement offre la conversione in versioni ricercabili e modificabili del file PDF originale. Può anche creare direttamente un PDF usando l'input da uno scanner, così come convertire formati di file non testuali in PDF modificabili/ricercabili.
2. I giusti parametri di scansione
Quando si scansionano documenti, è importante impostare i parametri giusti nelle impostazioni dello scanner. Alcuni di questi sono. Il principale di questi è l'orientamento. Assicuratevi che il documento sia inserito nello scanner con l'angolo corretto, perché una scansione inclinata può seriamente influenzare la precisione dell'OCR.
3. Impostazione della risoluzione
La migliore risoluzione per un OCR accurato è 300 dpi o punti per pollice. Questa densità più alta permette una scansione più "stretta", permettendo al motore OCR di lavorare con un numero doppio di punti di riferimento rispetto ai 150 dpi.
4. Selezione della modalità colore
Per documenti scoloriti o vecchi, RGB è la modalità colore raccomandata per permettere allo scanner di catturare completamente il contenuto del documento fisico. In generale, tuttavia, la scansione in modalità scala di grigi è l'opzione migliore per la precisione OCR. Anche se la modalità in bianco e nero aiuta l'immagine ad essere scansionata ad una velocità maggiore, questo potrebbe influenzare la qualità del riconoscimento del testo.
5. Regolazioni di luminosità e contrasto
Per la luminosità, entrambi gli estremi - troppo alto o troppo basso - possono influenzare negativamente la qualità e la precisione dell'OCR. Per questo motivo, il 50% è l'impostazione di luminosità raccomandata. Tuttavia, questo dipende anche dallo scanner stesso, quindi ci si può aspettare una fase iniziale di prove ed errori.
In termini di contrasto, l'impostazione più alta è solitamente preferita perché l'OCR funziona essenzialmente analizzando le aree scure e chiare per identificare i singoli caratteri. Vengono poi applicate delle regole per abbinare questi risultati con caratteri, testo e numeri conosciuti. Se il contrasto tra la parte scura del testo è alto rispetto alle porzioni non testuali circostanti, l'OCR è più accurato.
6. Correzione e decontaminazione delle immagini
Questi due componenti hanno un grande impatto sulla qualità della scansione OCR. La correzione dell'immagine copre aspetti come l'aumento della risoluzione, l'applicazione di correzioni di colore e la prova di diverse impostazioni di contrasto, mentre la decontaminazione comporta la rimozione di caratteri non testuali come icone, immagini non testuali, caratteri insoliti e così via. Entrambi sono importanti perché permettono al motore OCR di 'leggere' il documento in modo più accurato.
7. Attenta correzione manuale
A seconda di quanto accurato vuoi che sia il risultato finale, la correzione manuale può essere necessaria o meno. Se l'accuratezza è fondamentale, allora questo è un passo indispensabile nel processo di digitalizzazione degli archivi. Si tratta essenzialmente di una verifica umana per assicurare che i caratteri digitalizzati siano riconosciuti correttamente nel contesto dell'immagine digitalizzata. È un processo noioso e minuzioso, ma essenziale in molti casi.
PDFelement - Il miglior software OCR per la digitalizzazione degli archivi
PDFelement offre un motore OCR altamente accurato, ma porta anche diversi altri vantaggi al tavolo quando si tratta di digitalizzazione di archivi. Ecco alcune delle caratteristiche che lo rendono il software perfetto per OCR di PDF e scansioni.
- Funzionalità di modifica complete - Una volta convertito in un PDF modificabile, un documento può essere facilmente modificato utilizzando gli strumenti di modifica per immagini, testo, tabelle, grafici, piè di pagina/intestazioni , filigrane, collegamenti ipertestuali e altri contenuti.
- OCR multilingue - Se hai un documento con più di una lingua presente, puoi tranquillamente utilizzare PDFelement per il processo OCR. Supporta oltre 20 lingue, il che aiuta ad aumentare la precisione complessiva del riconoscimento del testo.
- Processo batch - L'OCR può essere eseguito su un batch di documenti, risparmiando così tempo nel processo di archiviazione digitale.
- Annotazioni: i file convertiti possono essere annotati con note, evidenziazioni e altri contenuti, che aiutano il processo di indicizzazione. L'elenco delle annotazioni e il layout a schede di PDFelement facilitano il riferimento incrociato dei testi durante la ricerca di un argomento particolare utilizzando i file OCR.
- Firma elettronica e sicurezza - I file possono essere firmati digitalmente o elettronicamente, nonché protetti da visualizzazione o modifica non autorizzate utilizzando la crittografia basata su password. Questo aiuta a convalidare l'autenticità di un documento e impedisce che vengano apportate modifiche. La redazione è un'altra utile funzionalità che gli utenti possono utilizzare per impedire la ricerca di informazioni sensibili.
- Organizzazione di file e pagine - Semplici modi per dividere e unire file, creare portfolio PDF, confrontare documenti dopo l'OCR, aggiungere/eliminare/riordinare pagine, estrarre pagine, ecc. .
- Riduzione dimensione file - La funzione Ottimizza PDF in PDFelement aiuta gli archivisti a memorizzare grandi quantità di informazioni in modo molto efficiente.
Per queste e altre ragioni, PDFelement è considerato uno dei migliori editor PDF per OCR e compiti correlati. Il software è anche una delle utility PDF premium più convenienti per le piccole aziende e le organizzazioni di livello enterprise, il che lo rende una soluzione praticabile per le aziende, le istituzioni educative e tutti i tipi di entità nei settori governativo, pubblico e privato.
Salvatore Marin
staff Editor