Lo scraping di PDF consiste nell'estrazione di dati dai file PDF utilizzando strumenti automatizzati. Con l'aumento della quantità di dati memorizzati nei file PDF, lo scraping dei PDF è diventato uno strumento cruciale per le aziende e i ricercatori che devono raccogliere e analizzare i dati in modo rapido e accurato. Lo scraping di PDF può estrarre dati come testo, tabelle e immagini dai file PDF, che possono poi essere analizzati utilizzando strumenti di analisi dei dati.
I file PDF spesso memorizzano dati importanti come report finanziari, articoli di ricerca e documenti governativi. Con gli strumenti di estrazione PDF, i ricercatori e le aziende possono estrarre e analizzare rapidamente i dati da questi file per ottenere informazioni e prendere decisioni basate sui dati. Questo rende lo scraping dei PDF uno strumento essenziale per le industrie orientate ai dati e i campi della ricerca.

In questo articolo
I benefici dello scraping dei PDF
Lo scraping dei PDF offre numerosi vantaggi alle aziende, ai ricercatori e ad altri professionisti che hanno bisogno di estrarre dati dai file PDF. Ecco alcuni dei principali vantaggi nell'uso dei PDF scraper:
- La produttività: i raschiatori PDF possono estrarre grandi quantità di dati in una frazione del tempo che ci vorrebbe per estrarre gli stessi dati manualmente. Questa maggiore produttività consente alle aziende e ai ricercatori di concentrarsi sull'analisi dei dati anziché passare ore a estrarli.
- Precisione: Gli scraper PDF utilizzano algoritmi avanzati per estrarre i dati in modo accurato, riducendo il rischio di errori che possono verificarsi durante l'estrazione manuale dei dati. Questo garantisce che i dati estratti siano affidabili ed essenziali per le decisioni basate sui dati.
- Rapporto costi-benefici: Automatizzando il processo di estrazione dei dati, i raschiatori di PDF possono ridurre significativamente il tempo e i costi associati all'estrazione manuale dei dati. Questo consente alle aziende e ai ricercatori di risparmiare denaro sulle risorse e sul personale necessario per l'estrazione manuale dei dati.
- La flessibilità: i raschiatori PDF possono estrarre vari tipi di dati, inclusi testi, tabelle e immagini, consentendo agli utenti di estrarre i dati specifici di cui hanno bisogno per le loro analisi. Questa flessibilità consente agli utenti di personalizzare l'estrazione dei dati in base alle proprie esigenze.
- Facilità d'uso: I raschiatori di PDF sono user-friendly e richiedono una conoscenza tecnica minima, rendendoli accessibili a molti utenti. Questa facilità d'uso riduce la curva di apprendimento associata all'estrazione manuale dei dati, rendendo il processo più efficiente nel complesso.
- Compatibilità: I raschiatori PDF possono estrarre dati da diversi formati e versioni, rendendoli compatibili con molti file PDF. Questa compatibilità garantisce che gli utenti possano estrarre dati da qualsiasi file PDF di cui hanno bisogno, indipendentemente dal suo formato o versione.
PDFelement come un estrattore di testo da PDF
PDFelement è un potente editor e convertitore PDF che può estrarre dati dai file PDF, rendendolo uno strumento utile per lo scraping dei PDF. Con le sue funzionalità avanzate e l'interfaccia utente intuitiva, PDFelement è un'ottima opzione per le aziende e i ricercatori che hanno bisogno di estrarre dati dai file PDF in modo rapido e preciso.


Alcune delle principali caratteristiche di PDFelement come PDF scraper includono:
- Estrazione dati: PDFelement consente agli utenti di estrarre dati dai file PDF utilizzando la sua avanzata tecnologia OCR (riconoscimento ottico dei caratteri). Gli utenti possono estrarre dati dai file PDF in vari formati, inclusi testo, tabelle e immagini.
- Personalizzazione: PDFelement offre un alto livello di personalizzazione per l'estrazione dei dati, consentendo agli utenti di scegliere i dati specifici che desiderano estrarre. Questa funzione è particolarmente utile per i ricercatori e le aziende che hanno bisogno di estrarre punti dati specifici per le loro analisi.
- Automazione: PDFelement può automatizzare il processo di estrazione dati, risparmiando tempo agli utenti e riducendo il rischio di errori che possono verificarsi durante l'estrazione manuale dei dati.
- Compatibilità: PDFelement può estrarre dati da file PDF di diversi formati e versioni, rendendolo uno strumento versatile per l'estrazione di dati.
- Interfaccia utente intuitiva: PDFelement è facile da usare, anche per gli utenti con conoscenze tecniche limitate. La sua interfaccia intuitiva e il design semplice lo rendono accessibile a molti utenti.
Come utilizzare PDFelement come PDF Scraper
Utilizzare PDFelement come un estrattore di PDF è un processo semplice. Ecco una guida passo passo su come utilizzare PDFelement come PDF scraper:
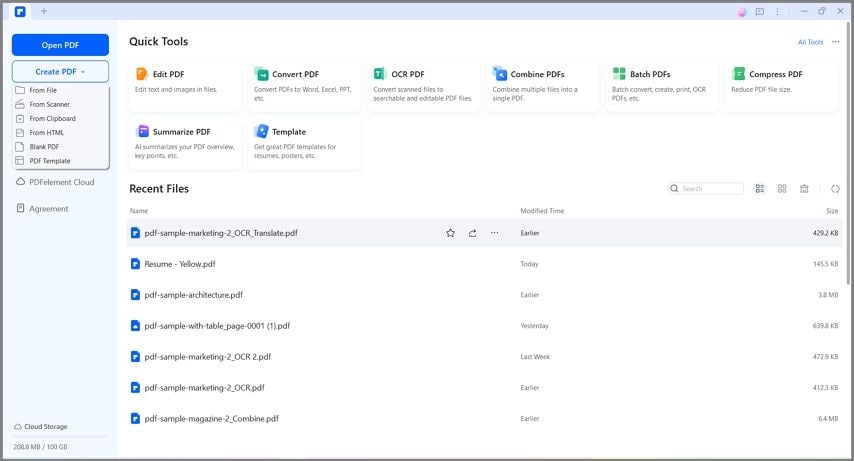
Passo1
Apri PDFelement e carica il tuo modulo PDF trascinandolo o utilizzando il pulsante "Apri PDF".
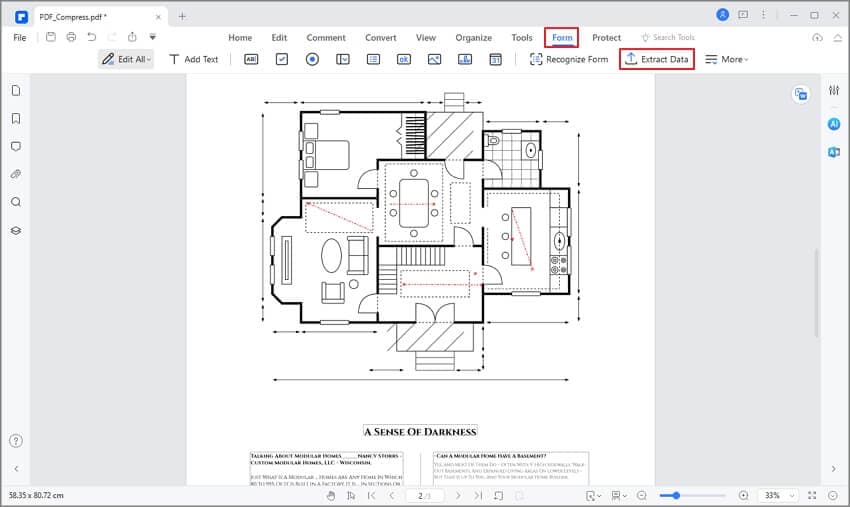
Passo2
Clicca su "Form" > "Estrai Dati" per aprire una nuova finestra di dialogo.
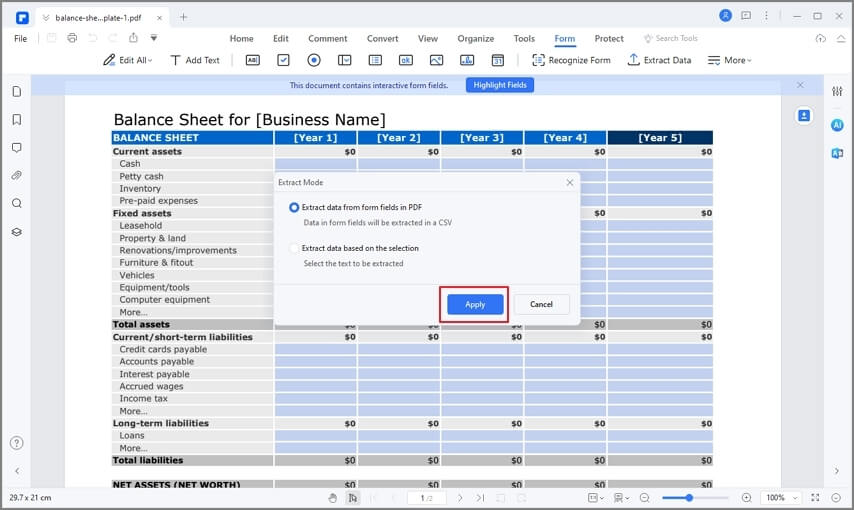
Passo3
Seleziona "Estrai dati dai campi del modulo in PDF" e clicca "Applica."
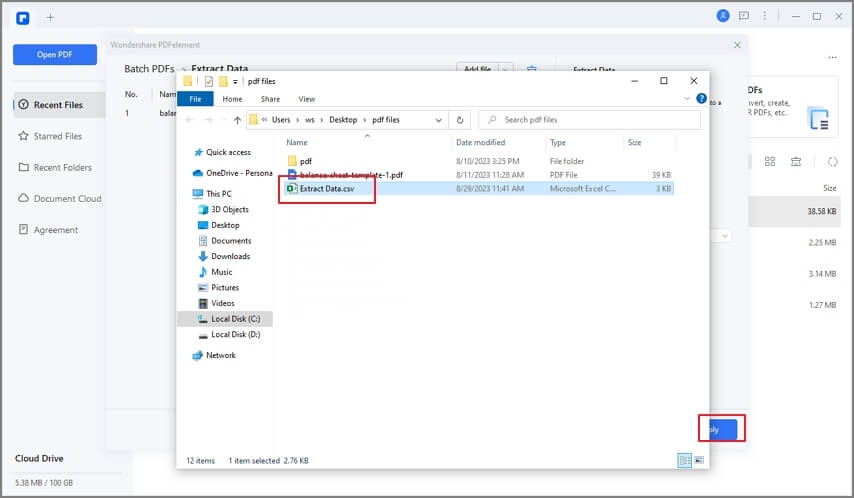
Passo4
Il programma estrarrà i dati in un file CSV. Clicca su "Apri" per accedere ai dati una volta completato il processo.
Ecco alcuni suggerimenti e trucchi per estrarre in modo efficiente i dati da PDF utilizzando PDFelement:
- Utilizza la funzione OCR per estrarre dati da file PDF scannerizzati che non contengono testo ricercabile.
- Utilizza la funzione di elaborazione batch per estrarre dati da più file PDF
- Utilizza la funzione dei modelli di estrazione dati per risparmiare tempo nell'estrazione dei dati da file PDF simili.
- Utilizza la funzione di anteprima per controllare l'accuratezza dei dati estratti prima di esportarli in un altro formato di file.
Nel complesso, PDFelement è uno strumento potente e facile da usare per l'estrazione di testo dai PDF. Seguendo questi passaggi e consigli, puoi estrarre dati in modo efficiente dai file PDF e risparmiare tempo sull'estrazione manuale dei dati.
Vantaggi nell'uso di PDFelement come PDF Scraper
Sono disponibili diversi strumenti per l'estrazione di dati da PDF, tra cui Adobe Acrobat, Tabula, PDFTables e PDFelement. Anche se ogni strumento ha punti di forza e debolezze, PDFelement si distingue in molti modi.
Rispetto ad altri strumenti di estrazione PDF, PDFelement offre un'interfaccia più user-friendly e intuitiva. Il suo processo di estrazione dati è semplice ed efficiente, permettendo agli utenti di estrarre facilmente i dati dai file PDF. La funzione OCR di PDFelement consente anche di estrarre il testo dai PDF scannerizzati, cosa che molti altri strumenti di estrazione PDF non possono fare.
La funzione di modelli di estrazione dati di PDFelement offre anche un vantaggio significativo. Con questa funzione, gli utenti possono risparmiare tempo creando modelli per file PDF simili, che possono poi essere utilizzati per estrarre i dati con pochi clic. Questa funzione è particolarmente utile per gli utenti che hanno bisogno di estrarre dati da più file PDF con una struttura simile.
Un altro vantaggio di PDFelement come PDF scraper è la sua funzione di elaborazione batch. Gli utenti possono estrarre dati da più file PDF contemporaneamente, risparmiando tempo e aumentando la produttività. Questa funzione è particolarmente utile per le aziende o le organizzazioni che gestiscono grandi quantità di dati.
PDFelement offre anche diverse opzioni di esportazione, tra cui Excel, CSV e formati di testo semplice, rendendo facile per gli utenti analizzare i dati estratti in altri programmi o software. PDFelement fornisce potenti strumenti di pulizia e manipolazione dei dati, come la formattazione del testo e la fusione delle tabelle, consentendo agli utenti di preparare i dati estratti per ulteriori analisi.
Scenari di PDFelement Scraper
Le capacità di estrazione dati di PDFelement sono utili in una vasta gamma di scenari. Questa sezione esplorerà alcuni dei casi d'uso più comuni in cui lo strumento di estrazione di PDFelement può essere particolarmente vantaggioso.
Ricerca
La ricerca è un campo che si basa pesantemente sull'analisi dei dati, e lo strumento di estrazione di PDFelement può essere utile per estrarre e analizzare dati da varie fonti.
Gli articoli accademici e i rapporti spesso contengono dati preziosi che i ricercatori devono estrarre e analizzare. Il raschietto di PDFelement può aiutare i ricercatori a estrarre i dati da questi documenti in modo rapido e preciso, riducendo il tempo e lo sforzo necessari per l'inserimento manuale dei dati.
I sondaggi e i questionari sono strumenti di ricerca comuni utilizzati per raccogliere dati dai partecipanti allo studio. Il raschietto di PDFelement può estrarre e analizzare i dati del sondaggio, risparmiando ai ricercatori tempo ed sforzi preziosi. Con PDFelement, i ricercatori possono facilmente convertire i risultati di un sondaggio in un formato utilizzabile, come un foglio di calcolo, consentendo un'analisi dei dati più semplice.
La ricerca governativa e di politica spesso comporta l'analisi di grandi quantità di dati, inclusi report, documenti di politica e testi legislativi. Il raschietto di PDFelement può estrarre dati rilevanti da questi documenti, consentendo ai decisori politici e ai ricercatori di identificare rapidamente modelli e tendenze.
La ricerca di mercato consiste nel raccogliere e analizzare dati sul comportamento dei consumatori, sulle tendenze di mercato e sull'attività dei concorrenti. Lo strumento di estrazione di PDFelement può estrarre dati da report di ricerca di mercato, analisi dei social media e altre fonti, consentendo alle aziende di ottenere preziose informazioni sulle tendenze di mercato e sul comportamento dei consumatori.
La ricerca medica e scientifica comporta l'analisi di grandi quantità di dati provenienti da varie fonti, tra cui studi clinici, cartelle cliniche e articoli di ricerca. Il raschietto di PDFelement può estrarre dati rilevanti da questi documenti, consentendo ai ricercatori di identificare modelli e tendenze utili nello sviluppo di nuovi trattamenti e terapie.

Business
Lo strumento di estrazione di PDFelement può essere utile anche per le aziende che devono estrarre e analizzare dati da varie fonti.
La fatturazione e la fatturazione comportano spesso il lavoro con grandi quantità di dati, inclusi informazioni sui clienti e storici degli acquisti. Il raschietto di PDFelement può estrarre questi dati dalle fatture e dalle dichiarazioni di fatturazione, consentendo alle aziende di identificare rapidamente i modelli e le tendenze di acquisto dei clienti.
La rendicontazione finanziaria comporta l'analisi dei dati provenienti da vari documenti finanziari, tra cui il bilancio, il conto economico e lo stato patrimoniale. Il raschietto di PDFelement può estrarre dati rilevanti da questi documenti, consentendo alle aziende di generare rapidamente report finanziari accurati.
La ricerca di mercato consiste nel raccogliere e analizzare dati sul comportamento dei consumatori, sulle tendenze di mercato e sull'attività dei concorrenti. Lo strumento di estrazione di PDFelement può estrarre dati da report di ricerca di mercato, analisi dei social media e altre fonti, consentendo alle aziende di ottenere preziose informazioni sulle tendenze di mercato e il comportamento dei consumatori.
La gestione delle risorse umane comporta la raccolta e l'analisi dei dati sulle prestazioni dei dipendenti, sull'assistenza e su altri fattori. Lo strumento di estrazione di PDFelement può estrarre dati rilevanti dalle valutazioni delle prestazioni, dalle schede presenze e da altri documenti HR, consentendo alle aziende di individuare tendenze e modelli nel comportamento dei dipendenti e prendere decisioni basate sui dati.
Legge
Lo strumento di estrazione di PDFelement può essere un'utile risorsa anche per i professionisti legali che desiderano estrarre e analizzare dati da vari documenti legali.
La scoperta è una parte importante del processo legale, che richiede agli avvocati di raccogliere e analizzare grandi quantità di dati da varie fonti. Lo strumento di estrazione di PDFelement può estrarre dati da documenti legali, inclusi contratti, accordi e depositi in tribunale, consentendo agli avvocati di identificare rapidamente informazioni rilevanti e costruire casi più solidi.
La gestione dei contratti è una parte importante di molte pratiche legali che coinvolge la revisione e l'analisi di grandi contratti e accordi. Il raschietto di PDFelement può estrarre dati rilevanti da questi documenti, consentendo agli avvocati di identificare rapidamente termini e disposizioni chiave, monitorare la conformità contrattuale e gestire il rischio.
La legge sulla proprietà intellettuale protegge e gestisce preziosi beni di proprietà intellettuale, tra cui brevetti, marchi e diritti d'autore. Lo strumento di estrazione di PDFelement può estrarre dati da documenti di proprietà intellettuale, consentendo agli avvocati di identificare rapidamente informazioni rilevanti e monitorare lo stato dei beni di proprietà intellettuale.
La ricerca legale analizza dati da varie fonti, tra cui giurisprudenza, leggi e regolamenti. Il raschietto di PDFelement può estrarre dati rilevanti da queste fonti, consentendo agli avvocati di trovare rapidamente informazioni pertinenti e costruire argomentazioni legali più solide.
Conclusione
Le capacità di estrazione PDF di PDFelement forniscono uno strumento potente per l'estrazione e l'analisi dei dati. Offre un'interfaccia utente intuitiva e una vasta gamma di funzionalità, rendendolo un'ottima scelta per ricercatori, analisti aziendali e professionisti legali. La sua capacità di estrarre dati in modo accurato e rapido dai PDF può risparmiare tempo e aumentare la produttività. PDFelement fornisce una soluzione economica per le organizzazioni che hanno bisogno di estrarre dati dai PDF frequentemente, consentendo loro di migliorare l'efficienza e ottimizzare il flusso di lavoro.